
编程上机考试
2024-07-23
简介:当我不断用Kimi写C++而一直报错使得我一下午都没有达成目标时,我意识到我不能在自己不懂C++的情况下完全交给AI去写代码,我至少得看得懂C++代码,以免AI只是在糊弄我。当我会C++之后,我可以用AI来减少重复,但我不可能对C++一知半解的情况下完成工作目标。
简介:基础不牢,地动山摇!这些年上的学,四年生物医学工程本科,三年电子信息(仪器仪表工程)硕士,着实让我没学到太多用得上的知识,现在工作最用得上的就只有上学时学的一点点编程的知识。想到这里,不禁感到痛心,我这些年并不是混日子,而且付出很多努力学习也很辛苦,但是奈何学到的东西大多没有用到,而我的光阴、斗志、兴趣、热情也都在这七年的时间中慢慢磨没了,怎能不让人痛心呢!工作之后,我意识到只有十年坚持一项事情、一个领域才可能在现实中找到立足之地,要是前面七年的东西能够用上,我的原始积累就有底气了,可惜没有。既然到了这个地步,就不要再纠结过去了,立足当下,忘掉过去,构建未来。
简介:学一下GPGPU-sim,也许比Gem5好重构。
简介:一直很懒没去考驾照,记录自己考驾照的知识点,逼自己考完。
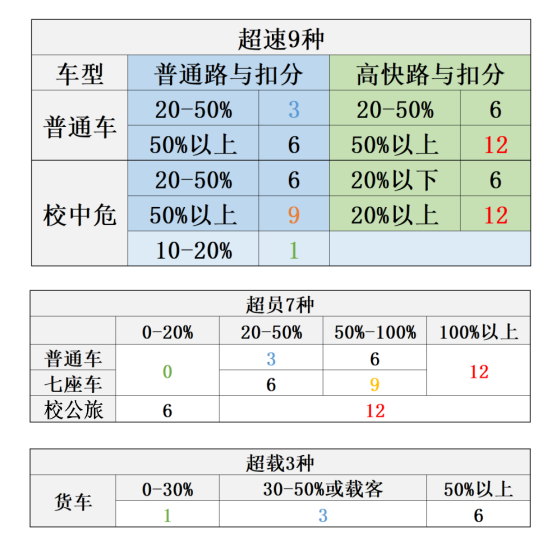
| 车辆 | 超速 | 普路 | 高速/城快路 |
|---|---|---|---|
| 普通车 | 20%~50% | 3分 | 6分 |
| 普通车 | 50%以上 | 3分 | 12分 |
| 校中危 | 10%~20% | 1分 | 6分 |
| 校中危 | 20%~50% | 6分 | 12分 |
| 校中危 | 50%以上 | 9分 | 12分 |
| 超过核定人数 | 7座以下 | 7座以上 |
|---|---|---|
| 20% ~ 50% | 3分 | 6分 |
| 50% ~ 100% | 6分 | 9分 |
高速低能见度速度
| 口诀 | 能见度 | 车速 | 跟车距离 |
|---|---|---|---|
| 261 | <200m | <=60Km/h | >=100m |
| 154 | <100m | <=40Km/h | >=50m |
| 520 | <50m | <=20Km/h | 尽快驶离 |
普通车:校车、中型以上载货载客汽车、危险物品运输车辆以外的机动车
公旅危:公路客运汽车、旅游客运汽车、危险物品运输车辆
普通客:校车、公路客运汽车、旅游客运汽车、7座以上载客汽车以外的其它载客车
| 关键词 | 犯错类型 | 扣分 |
|---|---|---|
| 车牌号 | 伪造、变造(包括行驶证、驾驶证、校车标牌),或使用其他车(行驶证) | 12分 |
| 未悬挂、故意遮挡、污损 | 9分 | |
| 不按规定安装,比如翘起 | 3分 | |
| 驾驶证 | 驾驶与准驾车型不符的机动车 | 9分 |
| 未取得校车驾驶资格驾驶校车 | 9分 | |
| 驾驶证被暂扣或者扣留期间驾驶启动车 | 6分 | |
| 未按时进行安全技术检验 | 校车,或存在安全隐患 | 3分 |
| 公旅危 | 3分 | |
| 公旅危以外的车 | 1分 | |
| 载运危险品、不可解体的物品 | 未按指定的时间、路线、速度行驶或未悬挂警示标志并有安全措施 | 6分 |
| 不可解体品,未按指定的时间、路线、速度行驶或未悬挂警示标志 | 6分 | |
| 未批准进入危险化学品运输车辆限制通行区域的 | 6分 | |
| 安全驾驶 | 饮酒驾驶(醉驾吊销驾驶证) | 12分 |
| 接打手持电话 | 3分 | |
| 不系安全带 | 1分 | |
| 摩托车不带头盔 | 1分 | |
| 疲劳驾驶 | 连续驾驶中危超过4小时未停车休息或者停车休息少于20分钟 | 9分 |
| 连续驾驶货车超过4小时未停车休息或者停车休息少于20分钟 | 6分 | |
| 车辆灯光、交通信号灯 | 不按交通信号灯指示通行(穿红灯) | 6分 |
| 在道路上车辆发生故障、事故停车后,不按规定使用灯光或设置警告标志 | 3分 | |
| 不按规定使用灯光 | 1分 | |
| 交通事故 | 造成致人轻伤以上或者死亡的交通事故后逃逸,尚不构成犯罪的 | 12分 |
| 造成致人轻微伤或者财产损失的交通事故后逃逸,尚不构成犯罪的 | 6分 | |
| 其它 | 代替实际机动车驾驶人接受交通违法行为处罚和记分牟取利益的 | 12分 |
| 违反禁令标志、禁止标线指示的 | 1分 | |
| 载货长度、宽度、高度超过规定 | 1分 | |
| 擅自改造的货车 | 1分 |
简介:工作需要,需要使用C++来使用Pytorch,学无止境呀!
在两眼一眼的情况下先问Kimi:首先,使用Pytorch进行模型训练最优的方式还是使用Python接口,简单易用,那么什么情况下需要用Pytorch的C++接口呢?—— 往往就是在模型部署推理阶段。其次,就看怎么实现模型C++部署:
unzip libtorch-cxx11-abi-shared-with-deps-2.3.1%2Bcpu.zip
2. 编写一个简单的C++代码测试LibTorch
```C++
// example-app.cpp
#include <torch/torch.h>
#include <iostream>
int main() {
torch::Tensor tensor = torch::rand({2, 3});
std::cout << tensor << std::endl;
}
set(CMAKE_CXX_STANDARD 17) set(CMAKE_CXX_STANDARD_REQUIRED ON)
find_package(Torch REQUIRED)
add_executable(example-app example-app.cpp)
target_link_libraries(example-app “${TORCH_LIBRARIES}”)
if(CMAKE_CXX_COMPILER_ID STREQUAL “GNU”) target_compile_options(example-app PRIVATE “-Wall” “-Wextra”) elseif(CMAKE_CXX_COMPILER_ID STREQUAL “Clang”) target_compile_options(example-app PRIVATE “-stdlib=libc++”) endif()
set_target_properties(example-app PROPERTIES CXX_STANDARD 17 CXX_STANDARD_REQUIRED ON )
4. 编译运行
```bash
mkdir build
cd build
cmake -DCMAKE_PREFIX_PATH=./libtorch ..
# 编译
make
# 运行
./example-app
另外,如果已经安装了Pytorch的Python库,那么不下载LibTorch也是可以编译运行的:
cmake -DCMAKE_PREFIX_PATH=`python3 -c 'import torch;print(torch.utils.cmake_prefix_path)'` ..
后知后觉,发现Pytorch官方LibTorch下载使用文档。
在自己电脑跑通,但在需要运行的国产机上报错:
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
/usr/bin/ld: ../libtorch/lib/libtorch.so: error adding symbols: file in wrong format
collect2: error: ld returned 1 exit status
make[2]: *** [CMakeFiles/example-app.dir/build.make:88:example-app] 错误 1
make[1]: *** [CMakeFiles/Makefile2:76:CMakeFiles/example-app.dir/all] 错误 2
make: *** [Makefile:84:all] 错误 2
使用uname -m才发现是ARM 64位(aarch64)的设备,看网上说需要源码编译。
先下载源码:
git clone https://github.com/pytorch/pytorch --recursive && cd pytorch
git checkout v1.2.0
git submodule sync
git submodule update --init --recursive
上面四条命令依次解释如下:
简单设置:
export USE_CUDA=False
export BUILD_TEST=False
将USE_CUDA设置为False意味着在编译或运行程序时,将不会使用CUDA,也就是说,程序将不会利用GPU进行加速。设置BUILD_TEST为False时,编译系统可能会跳过构建测试代码的步骤,这可以加快编译过程,特别是在不需要测试代码的情况下。
编译:
mkdir build && cd build
python3 ../tools/build_libtorch.py
编译完成之后,整理成libtorch:
# libtorch/
mkdir include
cp -r /home/kylin/zw/pytorch/torch/ ./include
cp -r /home/kylin/zw/pytorch/caffe2/ ./include
cp -r /home/kylin/zw/pytorch/c10/ ./include
cp -r /home/kylin/zw/pytorch/aten/src/ATen/ ./include
cp -r /home/kylin/zw/pytorch/aten/src/TH/ ./include
cp -r /home/kylin/zw/pytorch/aten/src/THCUNN/ ./include
cp -r /home/kylin/zw/pytorch/aten/src/THNN/ ./include
cp -r /home/kylin/zw/pytorch/build/build/lib ./
mkdir share
cp -r /home/kylin/zw/pytorch/torch/share/cmake ./share
文件结构:
├── include
│ ├── ATen
│ ├── c10
│ ├── caffe2
│ ├── TH
│ ├── THCUNN
│ ├── THNN
│ └── torch
├── lib
└── share
└── cmake
折腾了一番之后还是报错:
kylin@kylin-190:~/zw/CppTorch/build$ make
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
In file included from /home/kylin/zw/LibTorch/include/torch/csrc/WindowsTorchApiMacro.h:3,
from /home/kylin/zw/LibTorch/include/torch/csrc/api/include/torch/cuda.h:3,
from /home/kylin/zw/LibTorch/include/torch/csrc/api/include/torch/all.h:3,
from /home/kylin/zw/LibTorch/include/torch/csrc/api/include/torch/torch.h:3,
from /home/kylin/zw/CppTorch/example-app.cpp:1:
/home/kylin/zw/LibTorch/include/c10/macros/Export.h:44:10: fatal error: c10/macros/cmake_macros.h: 没有那个文件或目录
44 | #include "c10/macros/cmake_macros.h"
| ^~~~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
make[2]: *** [CMakeFiles/example-app.dir/build.make:63:CMakeFiles/example-app.dir/example-app.cpp.o] 错误 1
make[1]: *** [CMakeFiles/Makefile2:76:CMakeFiles/example-app.dir/all] 错误 2
make: *** [Makefile:84:all] 错误 2
简介:这是《从头开始构建大语言模型》的第三章。
本章涵盖:
- 探讨在神经网络中使用注意机制的原因
- 引入基本的自注意力框架,并逐步发展为增强的自注意力机制
- 实现一个因果注意力模块,允许LLMs每次生成一个token
- 用dropout屏蔽随机选择的注意力权重,以减少过拟合
- 将多个因果注意模块堆叠成一个多头注意模块
在前一章中,您学习了如何为训练LLMs准备输入文本。这涉及到将文本分割成单独的词和子词tokens,这些tokens可以编码为LLM的向量表示,即所谓的嵌入向量。
在本章中,我们将研究LLM架构本身的一个组成部分——注意机制,如图3.1所示。
 图 3.1 对LLM进行编码、在一般文本数据集上对LLM进行预训练以及在标记数据集上对其进行微调的三个主要阶段的模型流程图。这一章的重点是自注意力机制,这是LLM架构的一个组成部分。
图 3.1 对LLM进行编码、在一般文本数据集上对LLM进行预训练以及在标记数据集上对其进行微调的三个主要阶段的模型流程图。这一章的重点是自注意力机制,这是LLM架构的一个组成部分。
注意机制是一个复杂的主题,这就是为什么我们要用一整章来讨论它。我们将在很大程度上孤立地看待这些注意机制,并在机制层面上关注它们。在下一章中,我们将对LLM中自注意力机制的其余部分进行编程,以了解它的作用并创建一个模型来生成文本。
在本章的过程中,我们将实现注意机制的四种不同变体,如图3.2所示。
 图 3.2 该图描述了我们将在本章中编码的不同注意机制,在添加可训练权重之前,从简化版本的自注意开始。因果注意机制为自注意添加了一个掩码,允许LLM一次生成一个单词。最后,多头注意将注意力机制组织成多个头部,允许模型并行捕获输入数据的各个方面。
图 3.2 该图描述了我们将在本章中编码的不同注意机制,在添加可训练权重之前,从简化版本的自注意开始。因果注意机制为自注意添加了一个掩码,允许LLM一次生成一个单词。最后,多头注意将注意力机制组织成多个头部,允许模型并行捕获输入数据的各个方面。
图3.2所示的这些不同的注意力变体相互构建,目标是在本章结束时实现一个紧凑而有效的多头注意力实现,然后我们可以将其插入到LLM架构中,我们将在下一章中编程实现。
在我们深入研究本章后面LLMs的核心——自注意机制之前,在LLMs之前没有注意机制的架构会有什么问题?假设我们想开发一个语言翻译模型,将文本从一种语言翻译成另一种语言。如图3.3所示,由于源语和目的语的语法结构不同,我们不能简单地逐字翻译文本。
 图 3.3 在将文本从一种语言翻译成另一种语言时,例如将德语翻译成英语,不可能只是逐字翻译。相反,翻译过程需要上下文理解和语法对齐。
图 3.3 在将文本从一种语言翻译成另一种语言时,例如将德语翻译成英语,不可能只是逐字翻译。相反,翻译过程需要上下文理解和语法对齐。
为了解决我们无法逐字翻译文本的问题,通常使用具有两个子模块的深度神经网络,即所谓的编码器和解码器。编码器的工作是首先读取并处理整个文本,然后解码器生成翻译后的文本。
当我们在第1章(第1.4节,为不同的任务使用LLMs)中介绍变压器架构时,我们已经简要地讨论了编码器-解码器网络。在变压器出现之前,递归神经网络(RNN)是语言翻译中最流行的编码器-解码器架构。
RNN是一种神经网络,其中前一步的输出作为当前步骤的输入,使它们非常适合于文本等顺序数据。如果你不熟悉RNN,不要担心,你不需要知道RNN的详细工作原理来参与这个讨论;我们在这里更多地关注编码器-解码器设置的一般概念。
在编码器-解码器RNN中,输入文本被送入编码器,编码器依次处理文本。编码器在每一步更新其隐藏状态(隐藏层的内部值),试图在最终隐藏状态下捕获输入句子的整个含义,如图3.4所示。然后,解码器利用这个最终的隐藏状态开始生成翻译后的句子,一次一个单词。它还在每一步更新其隐藏状态,该状态应该携带下一个单词预测所需的上下文。
 图 3.4 在Transformer模型出现之前,编码器-解码器RNN是机器翻译的热门选择。编码器从源语言中获取一系列tokens作为输入,其中编码器的隐藏状态(中间神经网络层)编码整个输入序列的压缩表示。然后,解码器使用其当前的隐藏状态开始翻译,一个接一个的tokens。
图 3.4 在Transformer模型出现之前,编码器-解码器RNN是机器翻译的热门选择。编码器从源语言中获取一系列tokens作为输入,其中编码器的隐藏状态(中间神经网络层)编码整个输入序列的压缩表示。然后,解码器使用其当前的隐藏状态开始翻译,一个接一个的tokens。
我们不需要知道这些编码器-解码器RNN的内部工作原理,但这里的关键思想是编码器部分将整个输入文本处理为隐藏状态(存储单元)。然后,解码器接受这种隐藏状态来产生输出。你可以把这个隐藏状态想象成一个嵌入向量,这个概念我们在第二章讨论过。
编码器-解码器RNN的一个大问题和局限性是,在解码阶段,RNN不能直接访问编码器先前的隐藏状态。因此,它完全依赖于当前隐藏状态,它封闭了所有相关信息。这可能导致上下文的丢失,特别是在复杂的句子中,依赖关系可能跨越很长的距离。
对于不熟悉RNN的读者,没有必要理解或研究这种架构,因为我们将不会在本书中使用它。本节的要点是,编码器-解码器RNN有一个缺点,这激发了注意力机制的设计。
在Transformer LLMs之前,如前所述,通常使用RNN来完成语言建模任务,如语言翻译。RNN可以很好地翻译短句,但对于较长的文本就不太适用了,因为它们不能直接访问输入中的前一个单词。
这种方法的一个主要缺点是,RNN必须在将其传递给解码器之前以单一隐藏状态记住整个编码输入,如前一节中的图3.4所示。
因此,研究人员在2014年开发了RNN的Bahdanau注意机制(以相应论文的第一作者命名),该机制修改了编码器-解码器RNN,使解码器可以在每个解码步骤中选择性地访问输入序列的不同部分,如图3.5所示。
 图 3.5 使用注意机制,网络的文本生成解码器部分可以选择性地访问所有输入tokens。这意味着对于生成给定的输出tokens,一些输入tokens比其他输入token更重要。重要性是由所谓的注意力权重决定的,我们将在后面计算。请注意,该图显示了注意力背后的一般思想,并没有描述Bahdanau机制的确切实现,这是本书范围之外的RNN方法。
图 3.5 使用注意机制,网络的文本生成解码器部分可以选择性地访问所有输入tokens。这意味着对于生成给定的输出tokens,一些输入tokens比其他输入token更重要。重要性是由所谓的注意力权重决定的,我们将在后面计算。请注意,该图显示了注意力背后的一般思想,并没有描述Bahdanau机制的确切实现,这是本书范围之外的RNN方法。
有趣的是,仅仅三年后,研究人员发现构建用于自然语言处理的深度神经网络并不需要RNN架构,并提出了原始的transformer架构(在第1章中讨论),该架构具有受Bahdanau注意机制启发的自注意机制。
自注意力是一种机制,它允许输入序列中的每个位置在计算序列表示时关注同一序列中的所有位置。自注意力机制是基于Transformer体系结构的当代LLMs(如GPT系列)的一个关键组成部分。
本章的重点是编码和理解GPT类模型中使用的这种自注意机制,如图3.6所示。在下一章中,我们将对LLM的其余部分进行编程。
 图 3.6 自注意力是Transformer中的一种机制,通过允许序列中的每个位置与同一序列中所有其他位置相互作用并权衡其重要性,用于计算更有效的输入表示。在本章中,我们将从头开始编写这种自我注意机制,然后在下一章中编写类似GPT的LLM的其余部分。
图 3.6 自注意力是Transformer中的一种机制,通过允许序列中的每个位置与同一序列中所有其他位置相互作用并权衡其重要性,用于计算更有效的输入表示。在本章中,我们将从头开始编写这种自我注意机制,然后在下一章中编写类似GPT的LLM的其余部分。
现在,我们将深入研究自我注意力机制的内部工作原理,并学习如何从头开始编写它。自注意力是每个基于Transformer体系结构的LLM的基石。
值得注意的是,这个主题可能需要大量的关注和注意(没有双关语的意思),但是一旦你掌握了它的基本原理,你就征服了本书中最难的一个方面,并在总体上实现了LLMs。
自注意力中的“自”
在自注意中,“自”指的是该机制通过关联同个输入序列中的不同位置来计算注意权重的能力。它评估和学习输入本身的各个部分之间的关系和依赖关系,例如句子中的单词或图像中的像素。这与传统的注意力机制形成了对比,传统的注意力机制关注的是两个不同序列元素之间的关系,比如在序列到序列模型中,注意力可能在输入序列和输出序列之间比较,如图3.5所示。
因为自我注意看起来很复杂,特别是当你第一次遇到它的时候,我们将在下一小节开始介绍一个简化版本的自我注意。之后,在3.4节中,我们将实现在LLMs中使用的具有可训练权值的自注意力机制。
在本节中,我们实现了一种简化的自注意力变体,没有任何可训练的权重,如图3.7所示。本节的目的是在3.4节添加可训练权重之前,说明自我注意力中的几个关键概念。
 图 3.7 自注意的目标是为每个输入元素计算一个上下文向量,它结合了来自所有其他输入元素的信息。在图中描述的示例中,我们计算上下文向量$z^{(2)}$。计算$z^{(2)}$的每个输入元素的重要性或贡献由注意力权重$α_{21}$到$α_{2T}$决定。在计算$z^{(2)}$时,注意力权重是根据输入元素$x^{(2)}$和所有其他输入来计算的。这些注意力权重的精确计算将在本节后面讨论
图 3.7 自注意的目标是为每个输入元素计算一个上下文向量,它结合了来自所有其他输入元素的信息。在图中描述的示例中,我们计算上下文向量$z^{(2)}$。计算$z^{(2)}$的每个输入元素的重要性或贡献由注意力权重$α_{21}$到$α_{2T}$决定。在计算$z^{(2)}$时,注意力权重是根据输入元素$x^{(2)}$和所有其他输入来计算的。这些注意力权重的精确计算将在本节后面讨论
图3.7给出了一个输入序列,用$x$表示,由$T$个元素组成,用$x^{(1)}$到$x^{(T)}$表示。这个序列通常表示文本,比如一个句子,它已经被转换成tokens嵌入,如第2章所述。
例如,考虑这样一个输入文本:“Your journey starts with one step.”,在这种情况下,序列的每个元素,例如$x^{(1)}$,对应于表示特定标记(如“Your”)的$d$维嵌入向量。在图3.7中,这些输入向量显示为三维嵌入。
在自注意力中,我们的目标是计算输入序列中每个元素$x^{(i)}$的上下文向量$z^{(i)}$。上下文向量可以解释为一个丰富的嵌入向量。
为了说明这个概念,让我们把重点放在第二个输入元素的嵌入向量$x^{(2)}$(对应于标记“journey”)和相应的上下文向量$z^{(2)}$上,如图3.7底部所示。这个增强的上下文向量$z^{(2)}$是一个包含关于$x^{(2)}$和所有其他输入元素$x^{(1)}$到$x^{(T)}$的信息的嵌入。
在自注意力中,语境向量起着至关重要的作用。它们的目的是通过合并序列中所有其他元素的信息来创建输入序列(如句子)中每个元素的丰富表示,如图3.7所示。这在LLMs中是必不可少的,因为LLMs需要理解句子中单词之间的关系和相关性。稍后,我们将添加可训练的权重,帮助LLM学习构建这些上下文向量,以便它们生成与LLM相关的下一个token。
在本节中,我们实现了一个简化的自注意力机制来一步一步地计算这些权重和结果上下文向量。
考虑下面的输入句子,它已经被嵌入到第2章讨论的三维向量中。我们选择了一个小的嵌入尺寸,以确保它适合没有换行的页面:
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
实现自我注意的第一步是计算中间值$ω$,称为注意力得分,如图3.8所示。
 图 3.8 本节的总体目标是说明使用第二个输入序列$x^{(2)}$作为query来计算上下文向量$z^{(2)}$。该图显示了第一个中间步骤,通过点积计算query $x^{(2)}$与所有其他输入元素之间的注意力分数$ω$。(请注意,图中的数字在小数点后被截断为一位,以避免混乱。)
图 3.8 本节的总体目标是说明使用第二个输入序列$x^{(2)}$作为query来计算上下文向量$z^{(2)}$。该图显示了第一个中间步骤,通过点积计算query $x^{(2)}$与所有其他输入元素之间的注意力分数$ω$。(请注意,图中的数字在小数点后被截断为一位,以避免混乱。)
图3.8说明了我们如何计算query token和每个输入token之间的中间注意力分数。我们通过计算query $x^{(2)}$与每个其他输入token的点积来确定这些分数:
query = inputs[1]
attn_scores_2 = torch.empty(inputs.shape[0])
for i, x_i in enumerate(inputs):
attn_scores_2[i] = torch.dot(x_i, query)
print(attn_scores_2)
计算出的注意分数如下:
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
理解点积
点积本质上是一种简洁的计算方法,将两个向量的逐元素相乘,然后将乘积相加,我们可以这样演示:
res = 0. for idx, element in enumerate(inputs[0]): res += inputs[0][idx] * query[idx] print(res) print(torch.dot(inputs[0], query))输出证实了逐元素乘法的和与点积的结果相同:
tensor(0.9544) tensor(0.9544)除了将点积运算视为一种将两个向量组合起来产生标量值的数学工具之外,点积还是一种相似性度量,因为它量化了两个向量对齐的程度:点积越高表示向量之间对齐或相似的程度越高。在自注意力机制的背景下,点积决定了序列中元素相互关注的程度:点积越高,两个元素之间的相似性和注意力得分越高。
在下一步中,如图3.9所示,我们将之前计算的每个注意力分数归一化。
 图 3.9 对输入query $x^{(2)}$计算出注意分数$ω_{21} \sim ω_{2T}$后,通过对注意分数进行归一化,得到注意力权重$α_{21} \sim α_{2T}$。
图 3.9 对输入query $x^{(2)}$计算出注意分数$ω_{21} \sim ω_{2T}$后,通过对注意分数进行归一化,得到注意力权重$α_{21} \sim α_{2T}$。
图3.9所示的归一化背后的主要目标是获得总计为1的注意力权重。这种规范化是一种惯例,对解释和维护LLM中的训练稳定性很有用。这里有一个实现这个规范化步骤的简单方法:
attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()
print("Attention weights:", attn_weights_2_tmp)
print("Sum:", attn_weights_2_tmp.sum())
如输出所示,注意力权重现在之和为1:
Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
Sum: tensor(1.0000)
在实践中,使用softmax函数进行规范化更为常见和可取。这种方法可以更好地管理极值,并在训练过程中提供更有利的梯度属性。下面是softmax函数的基本实现,用于规范化注意力分数:
def softmax_naive(x):
return torch.exp(x) / torch.exp(x).sum(dim=0)
attn_weights_2_naive = softmax_naive(attn_scores_2)
print("Attention weights:", attn_weights_2_naive)
print("Sum:", attn_weights_2_naive.sum())
如输出所示,softmax函数也满足目标,并将注意力权重归一化,使其总和为1:
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
此外,softmax功能确保注意力权重始终为正。这使得输出可以解释为概率或相对重要性,其中权重越大表示重要性越大。
注意,这个简单的softmax实现(softmax_naive)在处理大或小的输入值时可能会遇到数值不稳定问题,例如溢出和下溢。因此,在实践中,建议使用softmax的PyTorch实现,该实现已针对性能进行了广泛优化:
attn_weights_2 = torch.softmax(attn_scores_2, dim=0)
print("Attention weights:", attn_weights_2)
print("Sum:", attn_weights_2.sum())
在这种情况下,我们可以看到它产生的结果与之前的softmax_naive函数相同:
Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
Sum: tensor(1.)
现在我们计算了标准化的注意力权重,我们准备好了图3.10所示的最后一步:通过将嵌入的输入token $x^{(i)}$与相应的注意力权重相乘来计算上下文向量$z^{(2)}$,然后将结果向量相加。
 图 3.10 在计算并归一化注意力分数得到query $x^{(2)}$的注意权重后,最后一步是计算上下文向量$z^{(2)}$。这个上下文向量是所有输入向量$x^{(1)}$到$x^{(T)}$的组合,由注意力权重加权得到。
图 3.10 在计算并归一化注意力分数得到query $x^{(2)}$的注意权重后,最后一步是计算上下文向量$z^{(2)}$。这个上下文向量是所有输入向量$x^{(1)}$到$x^{(T)}$的组合,由注意力权重加权得到。
图3.10所示的上下文向量$z^{(2)}$计算为所有输入向量的加权和。这包括将每个输入向量乘以其相应的注意力权重:
query = inputs[1] # 2nd input token is the query
context_vec_2 = torch.zeros(query.shape)
for i,x_i in enumerate(inputs):
context_vec_2 += attn_weights_2[i]*x_i
print(context_vec_2)
计算结果如下:
tensor([0.4419, 0.6515, 0.5683])
在下一节中,我们将推广计算上下文向量的这个过程,以同时计算所有上下文向量。
在上一节中,我们计算了输入2的注意力权重和上下文向量,如图3.11中突出显示的行所示。现在,我们将这个计算扩展到计算所有输入的注意力权重和上下文向量。
 图 3.11 突出显示的行显示了第二个输入元素作为查询的注意力权重,正如我们在前一节中计算的那样。本节概括计算以获得所有其他注意力权重。
图 3.11 突出显示的行显示了第二个输入元素作为查询的注意力权重,正如我们在前一节中计算的那样。本节概括计算以获得所有其他注意力权重。
我们遵循与前面相同的三个步骤,如图3.12所示,只是在代码中做了一些修改,以计算所有上下文向量,而不是只计算第二个上下文向量$z^{(2)}$。
 图 3.12 在自注意力中,我们首先计算注意力分数,然后对其进行归一化以获得总和为 1 的注意力权重。这些注意力权重用于将上下文向量计算为输入的加权和。
图 3.12 在自注意力中,我们首先计算注意力分数,然后对其进行归一化以获得总和为 1 的注意力权重。这些注意力权重用于将上下文向量计算为输入的加权和。
首先,在图3.12所示的步骤1中,我们添加了一个额外的for循环来计算所有输入对的点积:
attn_scores = torch.empty(6, 6)
for i, x_i in enumerate(inputs):
for j, x_j in enumerate(inputs):
attn_scores[i, j] = torch.dot(x_i, x_j)
print(attn_scores)
得到的注意力得分如下:
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
前面张量中的每个元素表示每对输入之间的注意得分,如图3.11所示。注意,图3.11中的值是归一化的,这就是为什么它们不同于前面张量中未归一化的注意力得分。稍后我们会讨论归一化。
在计算前面的注意力分数张量时,我们在Python中使用了for循环。然而,for循环通常很慢,我们可以使用矩阵乘法获得相同的结果:
attn_scores = inputs @ inputs.T
print(attn_scores)
我们可以直观地确认结果与之前相同:
tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
在步骤2中,如图3.12所示,我们现在将每行归一化,使每行中的值之和为1:
attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)
这将返回以下与图3.10所示值匹配的注意权重张量:
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])
在我们进入步骤3(图3.12所示的最后一步)之前,让我们简单地验证一下这些行确实都和为1:
row_2_sum = sum([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
print("Row 2 sum:", row_2_sum)
print("All row sums:", attn_weights.sum(dim=-1))
结果如下:
Row 2 sum: 1.0
All row sums: tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
在第三步,也是最后一步,我们现在使用这些注意力权重通过矩阵乘法来计算所有上下文向量:
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
在结果输出张量中,每行包含一个三维上下文向量:
tensor([[0.4421, 0.5931, 0.5790],
[0.4419, 0.6515, 0.5683],
[0.4431, 0.6496, 0.5671],
[0.4304, 0.6298, 0.5510],
[0.4671, 0.5910, 0.5266],
[0.4177, 0.6503, 0.5645]])
通过将第二行与之前在3.3.1节中计算的上下文向量$z^{(2)}$进行比较,我们可以再次检查代码是否正确:
print("Previous 2nd context vector:", context_vec_2)
从结果可以看出,前面计算的context_vec_2与前面张量的第二行完全匹配:
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])
至此结束了简单的自关注机制的代码演练。在下一节中,我们将添加可训练的权重,使LLM能够从数据中学习并提高其在特定任务上的性能。
在本节中,我们将实现在原始Transformer体系结构、GPT模型和大多数其他流行的LLMs中使用的自注意力机制。这种自注意机制也被称为尺度点积注意力。图3.13提供了一个理想模型,说明这种自注意机制如何匹配实现LLM中的更广泛的上下文内容。
 图 3.13 该图是我们在本节编程的自注意机制如何适应本书和本章的更广泛文本内容的理想模型。在前一节中,我们编写了一个简化的注意机制来理解注意机制背后的基本机制。在本节中,我们将为这种注意机制添加可训练的权重。在接下来的部分中,我们将通过添加因果掩码和多个heads来扩展这种自注意机制。
图 3.13 该图是我们在本节编程的自注意机制如何适应本书和本章的更广泛文本内容的理想模型。在前一节中,我们编写了一个简化的注意机制来理解注意机制背后的基本机制。在本节中,我们将为这种注意机制添加可训练的权重。在接下来的部分中,我们将通过添加因果掩码和多个heads来扩展这种自注意机制。
如图3.13所示,具有可训练权重的自关注机制建立在前面的概念之上:我们想要计算上下文向量,作为特定于某个输入元素的输入向量的加权和。正如您将看到的,与我们之前在3.3节中编写的基本自注意机制相比,只有细微的区别。
最显著的区别是引入了在模型训练期间更新的权重矩阵。这些可训练的权重矩阵是至关重要的,这样模型(特别是模型中的注意力模块)就可以学会产生“好的”上下文向量。(注意,我们将在第5章训练LLMs。)
我们将在两个小节中讨论这种自我关注机制。首先,我们将像以前一样一步一步地编写代码。其次,我们将把代码组织到一个紧凑的Python类中,这个类可以导入到LLM架构中,我们将在第4章中对其进行编程。
我们将通过引入三个可训练的权重矩阵$W_q$、$W_k$和$W_v$来逐步实现自注意力机制。这三个矩阵用于将嵌入的输入token $x^{(i)}$投影到查询、键和值向量中,如图3.14所示。
 图 3.14 在具有可训练权矩阵的自注意力机制的第一步,我们计算输入元素$x$的查询($q$)、键($k$)和值($v$)向量。与前几节类似,我们将第二个输入$x^{(2)}$指定为查询输入。查询向量$q^{(2)}$是通过输入$x^{(2)}$和权重矩阵$W_q$之间的矩阵乘法得到的。同样,我们通过涉及权重矩阵$W_k$和$W_v$的矩阵乘法来获得键向量和值向量。
图 3.14 在具有可训练权矩阵的自注意力机制的第一步,我们计算输入元素$x$的查询($q$)、键($k$)和值($v$)向量。与前几节类似,我们将第二个输入$x^{(2)}$指定为查询输入。查询向量$q^{(2)}$是通过输入$x^{(2)}$和权重矩阵$W_q$之间的矩阵乘法得到的。同样,我们通过涉及权重矩阵$W_k$和$W_v$的矩阵乘法来获得键向量和值向量。
在前面的3.3.1节中,当我们计算简化的注意力权重以计算上下文向量$z^{(2)}$时,我们将第二个输入元素$x^{(2)}$定义为查询。之后,在3.3.2节中,我们将其推广到计算所有上下文向量$z^{(1)} \sim z^{(T)}$代表六个单词的输入句子“Your journey starts with one step.”。
同样,为了说明目的,我们将从只计算一个上下文向量$z^{(2)}$开始。在下一节中,我们将修改此代码以计算所有上下文向量。
让我们从定义几个变量开始:
x_2 = inputs[1]
d_in = inputs.shape[1]
d_out = 2
注意,在类似GPT的模型中,输入和输出维度通常是相同的,但是为了便于说明,为了更好地跟踪计算,我们在这里选择不同的输入(d_in=3)和输出(d_out=2)维度。
接下来,我们初始化三个权重矩阵$W_q$, $W_k$和$W_v$,如图3.14所示:
torch.manual_seed(123)
W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
请注意,我们设置requires_grad=False是为了减少输出中的混乱,但如果我们要使用权重矩阵进行模型训练,我们将设置requires_grad=True以在模型训练期间更新这些矩阵。
接下来,我们计算查询、键和值向量,如图3.14所示:
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)
根据查询的输出,我们可以看到,由于我们通过d_out将相应权重矩阵的列数设置为2,因此结果是一个二维向量:
tensor([0.4306, 1.4551])
权重参数vs注意力权重
注意,在权重矩阵$W$中,术语“权重”是“权重参数”的缩写,即在训练过程中优化的神经网络的值。不要将这与注意力权重混淆。正如我们在上一节已经看到的,注意力权重决定了上下文向量对输入的不同部分的依赖程度,即网络对输入的不同部分的关注程度。 总而言之,权重参数是定义网络连接的基本学习系数,而注意力权重是动态的,特定于上下文的值。
尽管我们的临时目标是只计算一个上下文向量$z^{(2)}$,但我们仍然需要所有输入元素的键和值向量,因为它们涉及计算相对于查询$q^{(2)}$的注意力权重,如图3.14所示。
我们可以通过矩阵乘法得到所有的键和值:
keys = inputs @ W_key
values = inputs @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
从输出中我们可以看出,我们成功地将6个输入标记从3D投影到2D嵌入空间:
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
第二步是计算注意力得分,如图3.15所示。
 图 3.15 注意分数计算是一个点积计算,类似于我们在3.3节简化的自注意机制中使用的计算。这里的新方面是,我们没有直接计算输入元素之间的点积,而是使用通过各自的权重矩阵转换输入获得的查询和键。
图 3.15 注意分数计算是一个点积计算,类似于我们在3.3节简化的自注意机制中使用的计算。这里的新方面是,我们没有直接计算输入元素之间的点积,而是使用通过各自的权重矩阵转换输入获得的查询和键。
首先,让我们计算注意力得分$ω_{22}$:
keys_2 = keys[1]
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
以下是未归一化注意力得分的结果:
tensor(1.8524)
同样,我们可以通过矩阵乘法将这个计算推广到所有注意力分数:
attn_scores_2 = query_2 @ keys.T # All attention scores for given query
print(attn_scores_2)
我们可以看到,作为快速检查,输出中的第二个元素与我们之前计算的attn_score_22匹配:
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])
第三步是从注意力得分到注意力权重,如图3.16所示。
 图 3.16 计算完注意力分数$ω$后,下一步就是使用softmax函数对这些分数进行归一化,得到注意力权重$α$。
图 3.16 计算完注意力分数$ω$后,下一步就是使用softmax函数对这些分数进行归一化,得到注意力权重$α$。
接下来,如图3.16所示,我们通过缩放注意力分数和使用我们之前使用的softmax函数来计算注意力权重。与之前的不同之处在于,我们现在通过除以键的嵌入维度的平方根来衡量注意力得分(注意,取平方根在数学上与取0.5的幂是一样的):
d_k = keys.shape[-1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
得到的注意权重如下:
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
缩放点积注意力背后的原理
采用嵌入维数归一化的原因是为了通过避免小梯度来提高训练性能。例如,当缩放嵌入维数时,对于类似GPT的LLMs,嵌入维数通常大于1000,由于应用了softmax函数,大的点积在反向传播期间可能导致非常小的梯度。随着点积的增加,softmax函数的行为更像阶跃函数,导致梯度接近于零。这些小的梯度会大大减慢学习速度或导致训练停滞。
这种自注意机制也被称为尺度点积注意力,原因是嵌入维数是平方根的尺度缩放。
现在,最后一步是计算上下文向量,如图3.17所示。
 图 3.17 在自注意计算的最后一步,我们通过注意权值将所有值向量组合计算上下文向量。
图 3.17 在自注意计算的最后一步,我们通过注意权值将所有值向量组合计算上下文向量。
与3.3节中计算上下文向量为输入向量的加权和类似,现在计算上下文向量为值向量的加权和。在这里,注意力权重作为加权因子,对每个值向量的各自重要性进行加权。与3.3节类似,我们可以使用矩阵乘法一步得到输出:
context_vec_2 = attn_weights_2 @ values
print(context_vec_2)
结果向量的内容如下:
tensor([0.3061, 0.8210])
到目前为止,我们只计算了一个上下文向量$z^{(2)}$。在下一节中,我们将泛化代码以计算输入序列$z^{(1)}$到$z^{(T)}$中的所有上下文向量。
为什么要查询、键和值?
注意机制上下文中的术语“键”、“查询”和“值”来自信息检索和数据库领域,其中使用了类似的概念来存储、搜索和检索信息。
“查询”类似于数据库中的搜索查询。它表示模型关注或试图理解的当前条目(例如,句子中的单词或tokens)。该查询用于探测输入序列的其他部分,以确定对它们的相关程度。
键”类似于用于索引和搜索的数据库键。在注意机制中,输入序列中的每个条目(例如,句子中的每个单词)都有一个关联的键。这些键用于匹配查询。
此上下文中的“值”类似于数据库中的键值对中的值。它表示输入项的实际内容或表示。一旦模型确定了哪些键(以及输入的哪些部分)与查询(当前关注项)最相关,它就会检索相应的值。
在前面的小节中,我们已经完成了计算自注意输出的许多步骤。这主要是为了说明目的,这样我们就可以一步一步地进行。在实践中,考虑到下一章的LLM实现,将这些代码组织成一个Python类是有帮助的,如下所示:
**清单3.1 一个紧凑的自注意力类**
import torch.nn as nn
class SelfAttention_v1(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.d_out = d_out
self.W_query = nn.Parameter(torch.rand(d_in, d_out))
self.W_key = nn.Parameter(torch.rand(d_in, d_out))
self.W_value = nn.Parameter(torch.rand(d_in, d_out))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attn_scores = queries @ keys.T # omega
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
在这段PyTorch代码中,SelfAttention_v1是一个派生自nn.Module的类,它是PyTorch模型的基本构建块,为模型层的创建和管理提供了必要的功能。
__init__方法为查询、键和值初始化可训练的权重矩阵(W_query、W_key和W_value),每个矩阵将输入维度d_in转换为输出维度d_out。
在前向传播过程中,使用forward函数,我们通过将查询和键相乘来计算注意力分数(attn_scores),并使用softmax对这些分数进行规范化。最后,我们用这些标准化的注意力得分来加权这些值,从而创建一个上下文向量。
我们可以这样使用这个类:
torch.manual_seed(123)
sa_v1 = SelfAttention_v1(d_in, d_out)
print(sa_v1(inputs))
由于输入包含六个嵌入向量,这就产生了一个存储六个上下文向量的矩阵:
tensor([[0.2996, 0.8053],
[0.3061, 0.8210],
[0.3058, 0.8203],
[0.2948, 0.7939],
[0.2927, 0.7891],
[0.2990, 0.8040]], grad_fn=<MmBackward0>)
作为快速检查,请注意第二行([0.3061,0.8210])是否匹配上一节中context_vec_2的内容。
图3.18总结了我们刚刚实现的自注意力机制。
 图 3.18 在自注意中,我们将输入矩阵$X$中的输入向量用三个权矩阵$W_q$、$W_k$、$W_v$进行变换。然后,我们根据结果查询(Q)和键值(K)计算注意力权重矩阵。使用注意力权重和值(V),我们然后计算上下文向量(Z)。(为了视觉上表达的清晰,我们在这个图中关注单个输入文本的n个tokens,而不是一批多个输入。因此,在这种情况下,3D输入张量被简化为2D矩阵。这种方法允许对所涉及的过程进行更直接的可视化和理解。)
图 3.18 在自注意中,我们将输入矩阵$X$中的输入向量用三个权矩阵$W_q$、$W_k$、$W_v$进行变换。然后,我们根据结果查询(Q)和键值(K)计算注意力权重矩阵。使用注意力权重和值(V),我们然后计算上下文向量(Z)。(为了视觉上表达的清晰,我们在这个图中关注单个输入文本的n个tokens,而不是一批多个输入。因此,在这种情况下,3D输入张量被简化为2D矩阵。这种方法允许对所涉及的过程进行更直接的可视化和理解。)
如图3.18所示,自注意涉及可训练权矩阵$W_q$、$W_k$、$W_v$。这些矩阵将输入数据转换为查询、键和值,这是注意力机制的关键组成部分。随着模型在训练过程中接触到更多的数据,它会调整这些可训练的权重,我们将在接下来的章节中看到。
我们可以利用PyTorch的nn.Linear来进一步改进SelfAttention_v1的实现。当bias单元被禁用时,其可以有效地执行矩阵乘法。此外,使用nn.Linear而不是手动实现nn.parameter (torch.rand(…))的一个显著优势是nn.Linear具有优化的权值初始化方案,有助于更稳定有效的模型训练。
**清单3.2 使用PyTorch的Linear层的自关注意力类**
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out, qkv_bias=False):
super().__init__()
self.d_out = d_out
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attn_scores = queries @ keys.T
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
context_vec = attn_weights @ values
return context_vec
你可以使用SelfAttention_v2类似于SelfAttention_v1:
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in, d_out)
print(sa_v2(inputs))
输出为:
tensor([[-0.0739, 0.0713],
[-0.0748, 0.0703],
[-0.0749, 0.0702],
[-0.0760, 0.0685],
[-0.0763, 0.0679],
[-0.0754, 0.0693]], grad_fn=<MmBackward0>)
注意,SelfAttention_v1和SelfAttention_v2给出不同的输出,因为它们对权重矩阵使用不同的初始权重,nn.Linear使用更复杂的权重初始化方案。
练习3.1比较SelfAttention_v1和SelfAttention_v2
简介:我常常在B站上看到UP主们将他们在桌面的操作制作成精美的视频,有时候还能局部放大以突出展示某一操作,我不知道怎么做到的,但我很想学会。所以,这值得探索一番。
我询问Kimi之后,打算最先尝试ScreenToGif。